GAE上搭建KindleEar实现自动RSS抓取订阅
更新日期:
引言
Kindle的邮件推送服务是这个产品很重要的一环,或者说一个功能。作为Kindle的使用者,我们需要用好这个邮件推送服务。在很多场合下,我们更希望用Kindle看或者订阅一些具有时效性的内容,于是笔者想到了RSS,能不能将RSS和Kindle结合,定期地将网页内容自动同步推送到Kindle设备上,从而订阅多个网站的内容呢?答案是可以的。使用Kindle订阅RSS新闻,目前笔者找到了有一下这几个网站或者方法可供选择。
狗耳朵 (http://www.mydogear.com/)
概要:首选,内置非常多的RSS源,但是缺点是免费用户不能推送图片,不能添加自定义RSS,而且还可能有广告。
ReadCola (http://readcola.com/)
概要:非常好的选择,可以生成期刊格式(Periodical),可以支持自定义RSS,支持推送图片,但是缺点是免费的RSS数量限定为16个。
Kindle4Rss (http://kindle4rss.com/)
概要:免费用户的限制是12个订阅RSS,总共2mb的图片,而且是手动投递。这样就失去了自动的意义,没什么意思。
HiKindle (http://www.hikindle.com/)
概要:里面有固定组合的RSS精选可供免费用户使用,有图片,可自动投递。里面还有各种杂志期刊供付费用户使用,笔者已经购买了它的付费服务,但是发现里面的很多杂志并不是期刊格式而只是普通的电子书格式,带目录,所以笔者只是订阅了其中的一本
Calibre
概要:在电脑上下载calibre软件,里面有一个Fetch News功能,而且内置了很多优秀的RSS可供选择,可以自定义RSS,生成的电子书为期刊格式,排版精美。缺点就是像这样在本地运行软件的方法显然是不能实现自动投递的,要抓取新闻需要电脑开着并且软件在运行才行。

改进方法
鉴于此现状,有人将Calibre的抓取RSS并生成期刊电子书的模块单独弄出来,写了一个可以部署到GAE(Google App Engine)上面运行的一个APP,这样的话,在GAE上面部署了这样一个应用,就可以实现通过网站自动抓取RSS并且自动推送了。它就是KindleEar,目前源代码托管在Github上。
部署方法
准备工作
- 首先,你得有一个
Gmail账号,并且电脑上安装了Python(2.7.5)。至于如何申请一个Google Gmail账号,在此不再赘述。
新建APP
- 在Google App Engine上面新建一个
APP,APP名字自定,记下APP的ID。
下载uploader
- 理论上需要安装
GoogleAppEngine SDK,可以从官网上搜索并下载安装,SDK用来调整APP的配置等,但实际上此处我们只用把APP上传上去就行了,KindleEar的作者写了一个单独的upload模块,可以在这里下载(同时笔者提供一个百度网盘的备用地址,提取码为:m7ic)。因此我们可以不用安装GoogleAppEngine SDK而直接下载此uploader并且解压到任意地方就行了。
下载Kindleear源码
- 如果电脑上安装了
git可以:
1 2 3 | cd /path/to/kindleear_uploader/
git clone https://github.com/cdhigh/KindleEar.git
mv KindleEar kindleear
|
- 当然也可以从项目主页下载
zip打包的源码,解压出来一个文件夹,再将此文件夹放到kindleear_uploader文件夹下,并重命名为kindleear。
上传
- 如果是
Windows用户,则直接运行uploader.bat并按照提示操作即可,如果是Linux用户或者Mac用户,则在kindleear_uploader下编写如下脚本保存并运行:
1 2 3 4 5 6 7 8 | ptbsare@ptbsare-PC ~ $ cd kindleear_uploader ptbsare@ptbsare-PC ~/kindleear_uploader $ cat uploader.sh #!/bin/bash export PYTHONPATH=./DLLs/:./libs/:./lib/:$PYTHONPATH python helper.py python appcfg.py --skip_sdk_update_check update kindleear/app.yaml kindleear/module-worker.yaml ptbsare@ptbsare-PC ~/kindleear_uploader $ chmod u+x uploader.sh ptbsare@ptbsare-PC ~/kindleear_uploader $ ./uploader.sh |
- 然后按照提示操作即可,但是能成功上传的前提是你所在的网络能够访问得到
Google网站和Google App Engine服务。假如说是用某工具作为梯子的话,那么怎么在命令行下使用代理呢?这里以该某工具作为梯子为例,在执行上传之前,先执行一下两条命令即可。
1 2 | export http_proxy=http://127.0.0.1:8087 export https_proxy=$http_proxy |
- 上传成功之后,你就可以打开你的网页页面了,地址为
YOUR_APP_ID.appspot.com
,同前所述,能打开此页面的前提是你能够访问得到Google的站点,要注意的是如果你用上文提到过的某工具作为梯子的话你是仍然无法打开你的网页页面的,理由就在于它们同都是托管在GAE上的,这里给出如下一个地址,可以尝试用如下地址代理打开:
1 | YOUR_APP_ID.appsp0t.com |
- 例如笔者打开之后页面是这个样子的
绑定域名。
- 如果无需绑定域名,那么部署部分就到这里结束了,下面介绍如何绑定域名。
- 登录到 Google Developers Console,然后的选择你的
project,点击进入到dashboard页面。在左侧目录树中一次选择Compute>App Engine>Settings。然后右侧的设置页面的顶部可以看到两个标签页:Application settings和Custom domains。选择Custom domains,就会看到三个选项的页面: - 在第一项上填上自己的域名然后点
Verify(验证),按照指示让Google验证你是该域名的真实拥有者,其中验证有多种方法,笔者推荐添加TXT记录的方式进行验证。 - 成功验证后在第二项填入你要绑定的顶级域名或者二级域名,如果是顶级域名,则需要在你的域名提供商那里将第三项所列出的指向
Google服务器的DNS记录全部添加上去;如果是二级域名,则需要按照第三项的指示在你的域名提供商那里添加一条CNAME记录。
首次登录
- 首次登录,用户名和密码均为
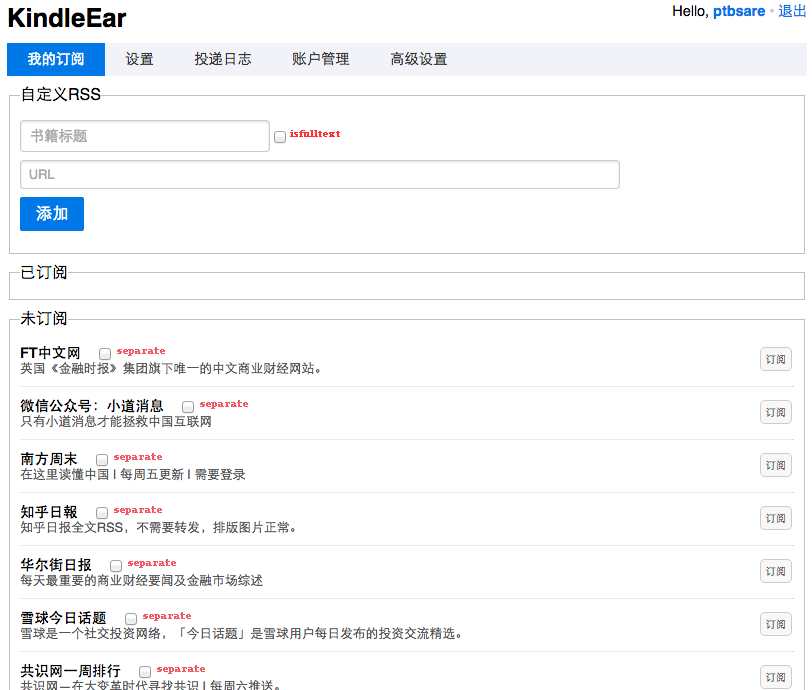
admin,你可以以管理员身份建立多个新用户,倘若点击某些选项卡出现internal server error的错误,说明网站的index尚未建立或者生成,GAE会自然生成这些index一般这个过程要持续数十分钟或者数小时。 - 在我的订阅下面会有很多已经写好的“书籍”可供订阅,
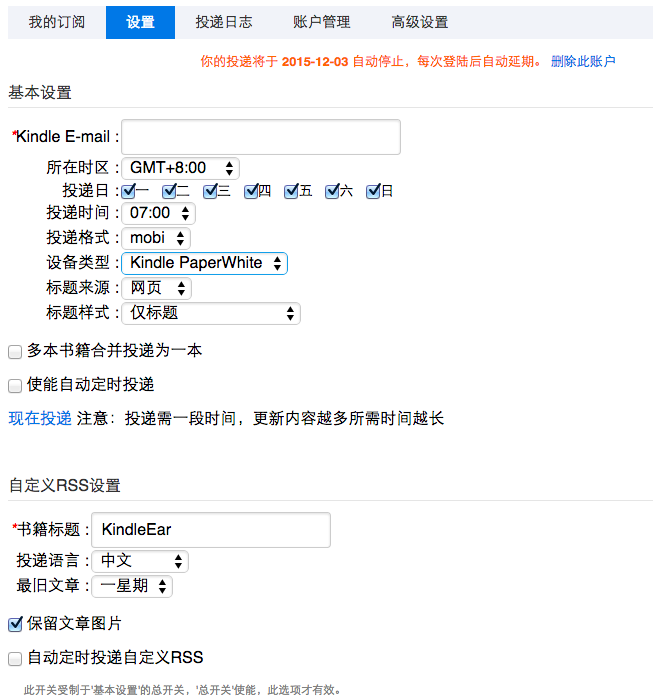
- 在设置选项卡下面可以设置Kindle邮箱,投递时间等等。
“书籍”的定制
书籍模版
KindleEar的很多模块提取自Calibre,那些内置的书籍模版其实是一个个py文件在其源码目录的books文件夹下,其中每个py文件类似于Calibre的recipe,作者实现了许多基本的类和功能,假如说有一点点python的基础的话,这样的书籍模版不难编写,笔者嫌内置的那些除了基本比如说经济学人之类的质量比较上乘的以外,其余的并不合笔者的胃口,并且笔者也懒得将一个个RSS输入到自定义RSS的框里面。下面来定制一本笔者自己的书籍,你可以看到定制以后抓取页面并生成的杂志是非常精美的。
一个基本模版
- 首先,笔者仿照里面现成的例子和写法,比葫芦画瓢,形成了下面一个基本的模版和例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = "ptbsare" __version__ = "0.1" from base import BaseFeedBook def getBook(): return tech class tech(BaseFeedBook): title = u'Tech News' __author__ = 'calibre' description = u'科技科普以及趣味精选。' language = 'zh-cn' feed_encoding = "utf-8" page_encoding = "utf-8" mastheadfile = "mh_technews.gif" coverfile = "cv_technews.jpg" network_timeout = 60 oldest_article = 7 max_articles_per_feed = 9 deliver_days = ['Friday'] oldest_article = 1 feeds = [ (u'YOUR_FEED_NAME','YOUR_FEED_URL') ] |
- 将文件保存为
tech.py,放到books文件夹下就形成了一本简单的书了。 - 在这个模版文件中,其中
tech类是继承自类BaseFeedBook,由于我们这本书主要是由RSS地址组成,所以需要继承这个类,该类作者在base.py中有具体的实现了很多功能。其中必须要指定的属性有:
1 2 3 4 5 6 7 | titile: 标明书籍的名称 description: 书籍的简介。 language: 书籍的语言,影响到默认调用的词典。 feeds: RSS源的地址,是一个元组列表,每个feed为一个元组(section,url,isfulltext) section : 章节名 url : rss/atom的链接 isfulltext : 是否是全文Feed,取值为TrueFalse,如果是非全文Feed,isfulltext可省略 |
- 在这个模版中,其余的属性,看名字就大致知道什么意思了,更多可定制的属性在
base.py中有详细的注释。
RSS 源地址
下面是笔者精心挑选的一个RSS集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | 36kr: http://www.36kr.com/feed?1.0 TechCrunch 中国: http://techcrunch.cn/feed/ 爱范儿: http://www.ifanr.com/feed Top News - MIT Technology Review: http://www.technologyreview.com/topnews.rss Hacker News: https://news.ycombinator.com/rss 麻省理工科技评论: http://zhihurss.miantiao.me/section/id/14 大公司日报: http://zhihurss.miantiao.me/daily/id/5 小道消息: http://hutu.me/feed 极客公园: http://www.geekpark.net/rss 极客范: http://www.geekfan.net/feed/ 人人都是产品经理: http://iamsujie.com/feed/ 邹剑波Kant: http://kant.cc/feed warfalcon: http://ys.8wss.com/rss/oIWsFtxo3oqejVy4KaJ4RDMVIrE0/ 豆瓣一刻: http://yikerss.miantiao.me/rss 环球科学: http://blog.sina.com.cn/rss/sciam.xml 科普公园: http://www.scipark.net/feed/ 科学松鼠会: http://songshuhui.net/feed 泛科学: http://pansci.tw/feed 果壳网: http://www.guokr.com/rss/ 果壳网科学人: http://feed43.com/8781486786220071.xml 简书推荐: http://jianshu.milkythinking.com/feeds/recommendations/notes Quora: http://www.quora.com/rss: True The Economist: China: http://www.economist.com/feeds/print-sections/77729/china.xml The Economist: Science and technology: http://www.economist.com/feeds/print-sections/80/science-and-technology.xml The Economist: Asia: http://www.economist.com/feeds/print-sections/73/asia.xml 知乎日报: http://zhihurss.miantiao.me/dailyrss 知乎精选: http://www.zhihu.com/rss 深夜食堂: http://zhihurss.miantiao.me/section/id/1 果壳网天文: http://feed43.com/3144628515834775.xml Matrix67: http://www.matrix67.com/blog/feed |
书籍封面与横幅
- 在上述模版中,
coverfile指定了封面图片的文件名,笔者从网上挑选了一张图片,并稍作处理,变成了下面的样子,作为封面:

- 其中封面图片的分辨率推荐为
600X800,并且为.jpg格式。将其命名为cv_technews.jpg并放到源码的images目录下。 - 同样的道理
mastheadfile为标题横幅图片,需要是.gif格式,分辨率为600X60,笔者自制了一张横幅标题,命名为mh_technews.gif并放到源码的images目录下。
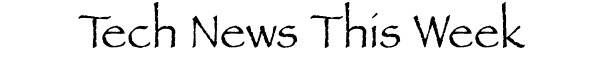
流量转发器
- 由于在实际运行中发现知乎日报屏蔽了来自GAE的访问请求,因此需要做一个
http的流量转发器转发流量,原作者在appfog部署了一个,笔者也自己搭建了一个转发器作为备用。 - 以原作者的为例:需要使用时,将
http请求改为
1 2 | http://forwarder.ap01.aws.af.cm/?k=xzSlE&t=timeout&u=URL 其中xzS1E为验证码,timeout为超时时间,可省略,默认为30s,URL则为你自己的URL |
- 同时在tech类中需要重写
fetcharticle函数,在此之前首先实现一个地址转换的函数:
1 2 3 | def url4forwarder(self, url): ' 生成经过转发器的URL ' return SHARE_FUCK_GFW_SRV % urllib.quote(url) |
- 其中
SHARE_FUCK_GFW_SRV是在config.py中被赋值为你所搭建的流量转发器的地址。
1 2 3 4 5 6 7 8 9 10 | def fetcharticle(self, url, opener, decoder): """链接网页获取一篇文章""" if self.fulltext_by_instapaper and not self.fulltext_by_readability: url = "http://www.instapaper.com/m?u=%s" % self.url_unescape(url) if "daily.zhihu.com" in url: url = self.url4forwarder(url) if "economist.com" in url: url = self.url4forwarder(url) return self.fetch(url, opener, decoder) |
- 遇到知乎日报和经济学人的文章使用流量转发器请求,转发流量,这样就不会遇到类似于
403(拒绝服务)的返回错误了。
最终书籍定制实现
下面是最终经过定制以后的书籍py文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | #!/usr/bin/env python # -*- coding:utf-8 -*- import re, datetime import urllib import json from bs4 import BeautifulSoup from lib.urlopener import URLOpener from base import BaseFeedBook from config import SHARE_FUCK_GFW_SRV from config import SHARE_SRV def getBook(): return tech class tech(BaseFeedBook): title = u'Tech News' __author__ = 'calibre' description = u'每周科技新闻精选,知乎问答精选,Quora精选,豆瓣,博客,经济学人China和Tech部分,各种科普,果壳天文,深夜食堂,数学精选。' language = 'zh-cn' feed_encoding = "utf-8" page_encoding = "utf-8" mastheadfile = "mh_technews.gif" coverfile = "cv_technews.jpg" network_timeout = 60 oldest_article = 7 max_articles_per_feed = 9 deliver_days = ['Friday'] feeds = [ ('36kr', 'http://www.36kr.com/feed?1.0'), (u'TechCrunch 中国', 'http://techcrunch.cn/feed/'), (u'爱范儿', 'http://www.ifanr.com/feed'), ('Top News - MIT Technology Review', 'http://www.technologyreview.com/topnews.rss'), ('Hacker News', 'https://news.ycombinator.com/rss'), (u'麻省理工科技评论', 'http://zhihurss.miantiao.me/section/id/14'), (u'大公司日报', 'http://zhihurss.miantiao.me/daily/id/5'), (u'小道消息', 'http://hutu.me/feed'), (u'极客公园', 'http://www.geekpark.net/rss'), (u'极客范', 'http://www.geekfan.net/feed/'), (u'人人都是产品经理', 'http://iamsujie.com/feed/'), (u'邹剑波Kant', 'http://kant.cc/feed'), ('warfalcon', 'http://ys.8wss.com/rss/oIWsFtxo3oqejVy4KaJ4RDMVIrE0/'), (u'豆瓣一刻', 'http://yikerss.miantiao.me/rss'), (u'环球科学', 'http://blog.sina.com.cn/rss/sciam.xml'), (u'科普公园', 'http://www.scipark.net/feed/'), (u'科学松鼠会', 'http://songshuhui.net/feed'), (u'泛科学', 'http://pansci.tw/feed'), (u'果壳网', 'http://www.guokr.com/rss/'), (u'果壳网科学人', 'http://feed43.com/8781486786220071.xml'), (u'简书推荐', 'http://jianshu.milkythinking.com/feeds/recommendations/notes'), ('Quora', 'http://www.quora.com/rss', True), ('The Economist: China', 'http://www.economist.com/feeds/print-sections/77729/china.xml'), ('The Economist: Science and technology', 'http://www.economist.com/feeds/print-sections/80/science-and-technology.xml'), ('The Economist: Asia', 'http://www.economist.com/feeds/print-sections/73/asia.xml'), (u'知乎日报', 'http://zhihurss.miantiao.me/dailyrss'), (u'知乎精选', 'http://www.zhihu.com/rss'), (u'深夜食堂', 'http://zhihurss.miantiao.me/section/id/1'), (u'果壳网天文', 'http://feed43.com/3144628515834775.xml'), ('Matrix67', 'http://www.matrix67.com/blog/feed'), ] def url4forwarder(self, url): ' 生成经过转发器的URL ' return SHARE_FUCK_GFW_SRV % urllib.quote(url) def url4forwarder_backup(self, url): ' 生成经过转发器的URL ' return SHARE_SRV % urllib.quote(url) def fetcharticle(self, url, opener, decoder): """链接网页获取一篇文章""" if self.fulltext_by_instapaper and not self.fulltext_by_readability: url = "http://www.instapaper.com/m?u=%s" % self.url_unescape(url) if "daily.zhihu.com" in url: url = self.url4forwarder(url) if "economist.com" in url: url = self.url4forwarder(url) return self.fetch(url, opener, decoder) |
更新内部书籍列表
- 在放好书籍文件之后,执行如下命令刷新APP数据:
1 2 | export PYTHONPATH=./DLLs/:./libs/:./lib/:$PYTHONPATH python appcfg.py --skip_sdk_update_check --verbose update kindleear |
- 再接着更新应用模块:
1 | python appcfg.py --skip_sdk_update_check update kindleear/app.yaml kindleear/module-worker.yaml |
- 接着打开网站应该就能看到名字为
Tech News的内置新增“书籍”了。

定制得到的书籍抓取
抓取到的杂志在Kindle里面的效果怎样呢?笔者以自己的Kindle Paperwhite 2为例,截屏演示效果。
杂志的封面

杂志的内部,部分目录及概要
- 前面的科技类新闻

- Hacker News,极客公园,大公司日报,产品经理

- 经济学人板块,和知乎日报

- 各种科普,数学精选

- 列表式目录
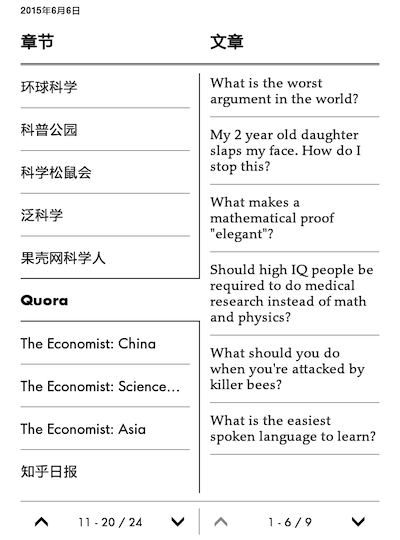
- 中文文章视图

- 英文文章视图

应用地址
- 笔者自己搭建的
KindleEar地址为:(http://kindleear.ptbsare.org/) - 由于
GAE免费应用的默认配额很有限,笔者发现抓取一次Tech News大概需要消耗1~2 个Backend Instance Hours,而Google提供的免费配额大概是每日9个Backend Instance Hours,用完则本日不能再抓取和投递新邮件。 - 笔者提供如下几个账号可供使用,如需额外更多的账号,请留言索取。
1 2 3 4 5 6 7 8 | 用户名 密码 lavender lavender twinkle twinkle solemn solemn hermit hermit seer seer zest zest david david |
更新
- 上面的Tech News仅仅在每周五推送,笔者将几个每日更新的RSS,另做了一个每天都投递的杂志,命名为Daily Digest,欢迎订阅,推荐在11点投递,目前包含如下几个RSS:
1 2 3 4 5 6 7 | 瞎扯 http://zhihurss.miantiao.me/section/id/2 豆瓣一刻 http://yikerss.miantiao.me/rss 知乎日报 http://zhihurss.miantiao.me/dailyrss 知乎精选 http://www.zhihu.com/rss 深夜食堂 http://zhihurss.miantiao.me/section/id/1 Quora http://www.quora.com/rss MIT科技评论 http://www.technologyreview.com/topnews.rss |
- 另外感谢
Life Memory的博主不给力的面条自制提供的知乎各个栏目的RSS地址。
